Analyse der Zitationsgruppen
Contents
Analyse der Zitationsgruppen#
Nachdem wir mittels der Netzwerkanalyse Subgruppen in unserem Zitationsnetzwerk ermitteln konnten, die nach innen besonders starke Verbindungen aufweisen, geht es nun darum, diese Subgruppen näher zu betrachten. Hier wenden wir drei verschiedene Möglichkeiten an, um den Inhalt, die Kategorienverteilung und besonders wichtige beteiligte Wissenschaftler:innen der einzelnen Zitationsgemeinschaften sichtbar zu machen.
Hierfür ist im ersten Schritt eine umfangreiche Datenvorbereitung (Schritt 1 und 2) nötig. Sodann können erstens die wichtigsten Paper nach unterschiedlichen Zentralitätsmaßen in Tabellen ausgegeben werden (Schritt 3). Der Inhalt wird zweitens über Wordclouds erforscht, die die häufigsten Worten in den Abstracts der Paper darstellen; in Kuchendiagrammen wird drittens außerdem die Verteilung der disziplinären Kategorien in den Subgruppen dargestellt (beide Schritt 4)
import csv
from operator import itemgetter
import networkx as nx
from networkx.algorithms import community
import pandas as pd
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
import numpy as np
import warnings # Future Warning (wegen drop-Befehl) unterdrücken
warnings.simplefilter(action='ignore', category=FutureWarning)
Einlesen der Daten#
# Pfad für Daten definieren
dataPath = "./network_graph"
# Knoten & deren Attribute als Dataframe einlesen
dfNodes = pd.read_csv(f'{dataPath}/citation_network_nodes.csv', delimiter=',')
# Knoten ohne Publikationsjahr, Titel oder Kategorie löschen
def cleaning(dfNodes):
dfNodes = dfNodes[dfNodes['publication_year'].notna()]
dfNodes = dfNodes[dfNodes['category'].notna()]
dfNodes = dfNodes[dfNodes['title'].notna()]
return dfNodes
dfNodes = cleaning(dfNodes)
# dfNodes.head(5)
# Knoten für historische Netzwerke einlesen
dfNodes_2015 = pd.read_csv(f'{dataPath}/citation_network_nodes_2015.csv', delimiter=',')
dfNodes_2015 = cleaning(dfNodes_2015).rename(columns={'index': 'label'})
dfNodes_2005 = pd.read_csv(f'{dataPath}/citation_network_nodes_2005.csv', delimiter=',')
dfNodes_2005 = cleaning(dfNodes_2005).rename(columns={'index': 'label'})
dfNodes_1995 = pd.read_csv(f'{dataPath}/citation_network_nodes_1995.csv', delimiter=',')
dfNodes_1995 = cleaning(dfNodes_1995).rename(columns={'index': 'label'})
Datenvorbereitung: Anzahl der Subgruppen einschränken#
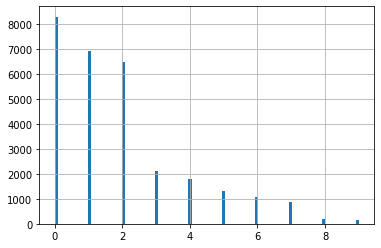
Zunächst schränken wir für die Analyse die Anzahl der betrachteten Subgruppen ein - wir betrachten im Folgenden sowohl für den Gesamtkorpus, als auch für die historischen Netzwerke die zehn größten Gruppen. Die untenstehenden Funktionen geben Informationen über die Anzahl aller Gruppen, die Anzahl der Paper in den größten Gruppen, etc. Im Histogramm wird deutlich, dass selbst die zehn größten Paper noch einen beinahe exponentiellen Größenanstieg verzeichnen - für die folgende Interpretation ist es also wichtig, diese Größenunterschiede im Blick zu behalten.
def modularity_info(dfNodes):
print(max(dfNodes.modularity), 'Subgruppen wurden ermittelt.')
dfModularityCount = dfNodes.modularity.value_counts().to_frame('count')
print(len(dfModularityCount[dfModularityCount['count'] <= 20]), 'davon umfassen weniger als 20 Paper.')
print(len(dfModularityCount[dfModularityCount['count'] >= 150]), 'umfassen mindestens 150 Paper.')
print('-----')
counts = dfNodes.modularity.value_counts()
print('Die größte Gruppe hat', list(counts)[0], 'Paper.')
print('Die 10t-größte Gruppe hat', list(counts)[9], 'Paper.')
print('-----')
# Der Datensatz für die Analyse der Subgruppen soll auf die wichtigsten Gruppen eingeschränkt werden
def generate_modularity_df(dfNodes):
modularity_info(dfNodes)
grenze = list(dfNodes.modularity.value_counts())[9]
print('Das Zitationsnetzwerk hat', len(dfNodes.index), 'Knoten.')
dfSubgroups = dfNodes.copy(deep=True) # Neues DF der Knoten erstellen
dfSubgroups = dfSubgroups[dfSubgroups.groupby('modularity').modularity.transform(len) >= grenze]
dfSubgroups['category'] = dfSubgroups['category'].str.strip('()').str.split(';') # Kategorien in list umwandeln
print(len(dfSubgroups.index), 'Knoten sind Teil einer Gruppe mit mindestens {} Papern.'.format(grenze))
return dfSubgroups
dfSubgroups = generate_modularity_df(dfNodes)
1096 Subgruppen wurden ermittelt.
1065 davon umfassen weniger als 20 Paper.
10 umfassen mindestens 150 Paper.
-----
Die größte Gruppe hat 8293 Paper.
Die 10t-größte Gruppe hat 171 Paper.
-----
Das Zitationsnetzwerk hat 32277 Knoten.
29185 Knoten sind Teil einer Gruppe mit mindestens 171 Papern.
dfSubgroups.tail(5)
| level_0 | index | publication_year | category | degree | title | in-degree | modularity | betweenness | label | |
|---|---|---|---|---|---|---|---|---|---|---|
| 32275 | 32275 | kerr e 2018 | 2018.0 | [Area Studies, History & Philosophy Of Scienc... | 4 | networked human network's human: humans in net... | 0 | 4 | 0.0 | kerr e 2018 |
| 32276 | 32276 | vasarhelyi o 2021 | 2021.0 | [Multidisciplinary Sciences] | 6 | gender inequities in the online dissemination ... | 0 | 2 | 0.0 | vasarhelyi o 2021 |
| 32277 | 32277 | fric u 2020 | 2020.0 | [Green & Sustainable Science & Technology, En... | 3 | role of computer software tools in industrial ... | 0 | 2 | 0.0 | fric u 2020 |
| 32278 | 32278 | gupta ak 2021 | 2021.0 | [Computer Science Interdisciplinary Applications] | 8 | performance analysis of naive bayes classifier... | 0 | 0 | 0.0 | gupta ak 2021 |
| 32279 | 32279 | zhou wz 2018 | 2018.0 | [Oncology] | 3 | identification of significant ego networks and... | 0 | 1 | 0.0 | zhou wz 2018 |
# Anzahl an Papern in den 10 größten Subgruppen
dfSubgroups.modularity.hist(bins=100)
<AxesSubplot:>
Datenvorbereitung: Verteilung der WoS-Kategorien in den Subgruppen#
In der nachfolgenden Analyse werden nicht mehr die Paper, sondern die Kategorien, die den Papern im WoS-Datensatz zugeordnet wurden, gezählt. Die untenstehenden Funktionen geben Informationen darüber aus, wie viele Kategorien in den Gruppen vertreten sind und wie viele Kategorien im Durchschnitt einem Paper zugeordnet wurden. Um die Interdisziplinarität der Subgruppen abzubilden wäre es in Zukunft auch sinnvoll, diesen Durchschnitt für jede Gruppe zu berechnen - das haben wir noch nicht implementiert.
Mithilfe eines Grenzwertes werden für die folgende Analyse außerdem Kategorien, die zu selten vorkommen, gelöscht. Dies ist vor allem wichtig, um die Darstellung in den Pie Charts aussagekräftig zu halten.
# Neues DF mit explode erstellen, um die einzelnen Kategorien in den Subgruppen zählen zu können
def generate_exp_df(dfSubgroups):
dfNodesExp = dfSubgroups.copy(deep=True)
dfNodesExp = dfNodesExp.explode('category')
dfNodesExp['category'] = dfNodesExp['category'].str.strip() # Leerzeichen entfernen
print('-----')
print('Allen Papern in den 10 größten Gruppen sind zusammen insgesamt', len(dfNodesExp), 'Kategorien zugeordnet.')
print('Das sind ca.', "{:.2f}".format(len(dfNodesExp)/len(dfSubgroups)), 'Kategorien pro Paper.')
print('-----')
return dfNodesExp
# DF umformatieren, Werte der Kategorien in den Subgruppen ausgeben
def format_exp_df(dfNodesExp):
dfNodesExp = dfNodesExp.groupby(by=['modularity','category']).count().unstack().reset_index()
dfNodesExp.columns = dfNodesExp.columns.map(lambda x: x[1]) # Multi-Index entfernen
dfNodesExp = dfNodesExp.loc[:,~dfNodesExp.columns.duplicated()] # Doppelte Spalten entfernen
dfNodesExp.fillna(0, inplace=True) # NaN mit 0 auffüllen
print('Insgesamt', (len(dfNodesExp.columns)-1), 'Kategorien sind in den 10 größten Subgruppen vertreten.')
return dfNodesExp
# Funktion, um zu bestimmten ab wann Kategorien zu selten in den Subgruppen vertreten sind, um angezeigt zu werden
def threshold(dfSubgroups):
counts = list(dfSubgroups.modularity.value_counts())
number = counts[9]/15 # Grenzwert wird auf 1/15tel der kleinsten Gruppe festgelegt
if number < 1:
return 1
return number
# Kategorien löschen, die in den jeweiligen Subgruppen weniger als 10 mal vertreten waren.
# Die gelöschten Kategorien können mit den untenstehenden print-Befehlen ausgegeben werden.
def delete_rare_cats(dfNodesExp, threshold):
z = 0
gelöscht = ''
for col in dfNodesExp:
if (dfNodesExp[col] <= threshold).all() == True:
gelöscht += (str(col) + ', ')
dfNodesExp = dfNodesExp.drop(col, 1)
z += 1
print(str(z) + ' Kategorien, die in den jeweiligen Subgruppen weniger als {:.2f} Mal vertreten waren, wurden gelöscht.'.format(threshold))
# print('Das waren folgende Kategorien: ' + str(gelöscht))
return dfNodesExp
def exp_df(dfSubgroups):
dfNodesExp = generate_exp_df(dfSubgroups)
dfNodesExp = format_exp_df(dfNodesExp)
grenzwert = threshold(dfSubgroups)
dfNodesExp = delete_rare_cats(dfNodesExp, grenzwert)
return dfNodesExp
dfNodesExp = exp_df(dfSubgroups)
-----
Allen Papern in den 10 größten Gruppen sind zusammen insgesamt 57008 Kategorien zugeordnet.
Das sind ca. 1.95 Kategorien pro Paper.
-----
Insgesamt 235 Kategorien sind in den 10 größten Subgruppen vertreten.
97 Kategorien, die in den jeweiligen Subgruppen weniger als 11.40 Mal vertreten waren, wurden gelöscht.
dfNodesExp.head(5)
| Agriculture Dairy & Animal Science | Agriculture Multidisciplinary | Anthropology | Archaeology | Architecture | Area Studies | Automation & Control Systems | Behavioral Sciences | Biochemical Research Methods | Biochemistry & Molecular Biology | ... | Statistics & Probability | Substance Abuse | Telecommunications | Transportation | Transportation Science & Technology | Urban Studies | Veterinary Sciences | Water Resources | Women's Studies | Zoology | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.0 | 8.0 | 82.0 | 1.0 | 5.0 | 9.0 | 172.0 | 6.0 | 45.0 | 8.0 | ... | 87.0 | 1.0 | 540.0 | 32.0 | 29.0 | 9.0 | 3.0 | 9.0 | 5.0 | 2.0 |
| 1 | 4.0 | 5.0 | 829.0 | 40.0 | 4.0 | 24.0 | 8.0 | 14.0 | 3.0 | 0.0 | ... | 110.0 | 48.0 | 28.0 | 21.0 | 9.0 | 30.0 | 4.0 | 11.0 | 17.0 | 3.0 |
| 2 | 2.0 | 43.0 | 97.0 | 0.0 | 10.0 | 36.0 | 37.0 | 8.0 | 6.0 | 2.0 | ... | 96.0 | 3.0 | 153.0 | 54.0 | 23.0 | 90.0 | 3.0 | 74.0 | 5.0 | 0.0 |
| 3 | 0.0 | 2.0 | 27.0 | 0.0 | 6.0 | 5.0 | 57.0 | 0.0 | 0.0 | 1.0 | ... | 161.0 | 2.0 | 75.0 | 15.0 | 5.0 | 8.0 | 0.0 | 5.0 | 1.0 | 0.0 |
| 4 | 1.0 | 27.0 | 78.0 | 1.0 | 16.0 | 25.0 | 2.0 | 6.0 | 0.0 | 0.0 | ... | 7.0 | 0.0 | 13.0 | 5.0 | 2.0 | 11.0 | 4.0 | 3.0 | 6.0 | 0.0 |
5 rows × 139 columns
Datenvorbereitung: Darstellung als Pie Charts#
Auch in diesem Schritt wird die Anzahl der abgebildeten Kategorien noch einmal verringert. Machen die Kategorien weniger als 2% aller Kategorien in einer Subgruppe aus, so wird ihr Wert aus dem Dataframe gelöscht - Kategorien die daraufhin in keiner Subgruppe mehr vorkommen, werden sodann vollständig gelöscht.
# DF für Pie Charts erstellen, in dem die Werte an der Größe der Subgruppe normalisiert werden
def generate_pie_df(dfNodesExp):
dfNodesPie = dfNodesExp.copy(deep=True)
dfNodesPie.insert(0,'sum','')
dfNodesPie['sum'].values[:] = 0
dfNodesPie = (dfNodesPie.T / dfNodesPie.T.sum()).T # Alle Spalten durch die Anzahl ihrer Summe teilen
dfNodesPie['sum'] = dfNodesPie[list(dfNodesPie.columns)].sum(axis=1) # Probe, ob überall 1
return dfNodesPie
# Werte, die kleiner als 0.02 sind, also weniger als 2% ausmachen, auf 0 setzen
# Zu kleine Werte werden so ignoriert, um später die Pie Charts nicht zu überfrachten
def delete_small_vals(dfNodesPie):
for col in dfNodesPie:
for i in range(len(dfNodesPie)):
if dfNodesPie[col][i] < 0.02:
dfNodesPie.at[i, col] = 0
return dfNodesPie
# Kategorien löschen, die nach der Normalisierung & Cleaning nur noch 0er-Werte haben
# Gelöschte Kategorien können mit dem untenstehenden print-Befehl ausgegeben werden
def delete_rare_cats_2(dfNodesPie):
z = 0
gelöscht = ''
for col in dfNodesPie:
if (dfNodesPie[col] == 0).all() == True:
gelöscht += (str(col) + ', ')
dfNodesPie = dfNodesPie.drop(col, 1)
z += 1
print('-----')
print(str(z) + ' Kategorien, die zu selten vertreten waren, wurden gelöscht.')
# print('Das waren folgende Kategorien: ' + str(gelöscht))
return dfNodesPie
def pie_df(dfNodesExp):
dfNodesPie = generate_pie_df(dfNodesExp)
dfNodesPie = delete_small_vals(dfNodesPie)
dfNodesPie = delete_rare_cats_2(dfNodesPie)
dfNodesPie = dfNodesPie.drop('sum', 1)
return dfNodesPie
dfNodesPie = pie_df(dfNodesExp)
dfNodesPie.head(5)
-----
93 Kategorien, die zu selten vertreten waren, wurden gelöscht.
| Anthropology | Architecture | Behavioral Sciences | Biology | Business | Communication | Computer Science Artificial Intelligence | Computer Science Cybernetics | Computer Science Hardware & Architecture | Computer Science Information Systems | ... | Public Environmental & Occupational Health | Social Sciences Interdisciplinary | Social Sciences Mathematical Methods | Sociology | Sport Sciences | Statistics & Probability | Telecommunications | Transportation | Veterinary Sciences | Zoology | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.088361 | 0 | 0 | 0.124771 | ... | 0 | 0.057459 | 0.03182 | 0 | 0 | 0 | 0.033044 | 0 | 0 | 0 |
| 1 | 0.068558 | 0 | 0 | 0 | 0.031757 | 0 | 0 | 0 | 0 | 0.021171 | ... | 0.028283 | 0.082451 | 0.031591 | 0.221386 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0.022977 | 0.024825 | 0 | 0 | 0.052623 | ... | 0.021772 | 0.088134 | 0 | 0.053587 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0.04219 | 0 | 0 | 0.051493 | ... | 0 | 0.068801 | 0.11164 | 0.027694 | 0 | 0.034833 | 0 | 0 | 0 | 0 |
| 4 | 0.0232 | 0 | 0 | 0 | 0.026472 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0.123736 | 0 | 0.209697 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 46 columns
# Farben für die Kategorien in den Pie Charts definieren, damit sie später vergleichbar sind
# Wichtig: Hier kann es bei Anwendung mit anderem Corpus/Ausschnitten zu Fehlermeldungen kommen, weil die Farben
# per Hand definiert sind und nicht alle Kategorien enthalten sind
colors={'Anthropology':'darkorange', 'Architecture': 'springgreen', 'Behavioral Sciences': 'blue',
'Biology': 'lime', 'Microbiology': 'lime', 'Business': 'goldenrod', 'Communication': 'darkorange',
'Computer Science Artificial Intelligence': 'dodgerblue', 'Computer Science Cybernetics': 'steelblue',
'Computer Science Hardware & Architecture': 'deepskyblue', 'Computer Science Information Systems': 'cadetblue',
'Computer Science Interdisciplinary Applications': 'skyblue', 'Computer Science Software Engineering': 'cornflowerblue',
'Computer Science Theory & Methods': 'royalblue', 'Ecology': 'forestgreen', 'Economics': 'gold',
'Business Finance': 'gold', 'Gerontology': 'sienna',
'Education & Educational Research': 'tomato', 'Education Scientific Disciplines': 'salmon',
'Engineering Electrical & Electronic': 'dimgray', 'Environmental Sciences': 'mediumseagreen',
'Environmental Studies': 'mediumaquamarine', 'Ergonomics': 'khaki', 'Evolutionary Biology': 'darkgreen',
'Geography': 'chartreuse', 'Green & Sustainable Science & Technology': 'yellowgreen',
'Health Policy & Services': 'yellow', 'Immunology': 'yellow',
'History & Philosophy Of Science': 'darkslategray', 'History Of Social Sciences': 'darkolivegreen',
'Humanities Multidisciplinary': 'peru', 'Infectious Diseases': 'yellow',
'Information Science & Library Science': 'darkgrey', 'Management': 'red',
'Mathematics Interdisciplinary Applications': 'maroon', 'Multidisciplinary Sciences': 'saddlebrown',
'Operations Research & Management Science': 'indianred', 'Philosophy': 'lightgreen',
'Physics Mathematical': 'lightgray', 'Physics Multidisciplinary': 'silver', 'Political Science': 'rosybrown',
'Psychology Experimental': 'coral', 'Psychology Multidisciplinary': 'darksalmon', 'Psychology': 'darksalmon',
'Psychology Mathematical': 'coral', 'Psychiatry': 'cyan', 'Psychology Clinical': 'coral',
'Psychology Developmental': 'coral', 'Psychology Applied': 'coral', 'Religion': 'cyan',
'Public Environmental & Occupational Health': 'violet', 'Social Sciences Interdisciplinary': 'purple',
'Social Sciences Mathematical Methods': 'orchid', 'Sociology': 'deeppink', 'Sport Sciences': 'turquoise',
'Social Sciences Biomedical': 'orchid', 'Social Work': 'turquoise',
'Statistics & Probability': 'cyan', 'Telecommunications': 'white', 'Transportation': 'wheat',
'Veterinary Sciences': 'sienna', 'Zoology': 'tan', 'Nursing': 'sienna',
'Family Studies': 'sienna', 'Hospitality Leisure Sport & Tourism': 'sienna',
'Mathematics Applied': 'maroon', 'Physics Fluids & Plasmas': 'lightgray', 'Psychology Social': 'coral',
'Criminology & Penology': 'coral', 'Crystallography': 'dimgray'}
Funktion für die Darstellung als Pie Charts#
Die untenstehende Funktion erzeugt aus den vorbereiteten Daten, die die Verteilung der häufigsten Kategorien in den Subgruppen enthalten, beschriftete Pie Charts.
def generate_piechart(subgruppe, df):
pie = df.iloc[subgruppe].plot.pie(colors=[colors[v] for v in df.iloc[0].keys()])
plt.axis("off")
plt.show(pie)
Datenvorbereitung: Die Darstellung der häufigsten Wörter in den Abstracts#
Mit den untenstehenden Funktionen werden die Abstracts der jeweiligen Paper eingelesen und Wordclouds ihrer häufigsten Worte für eine inhaltliche Interpretation erstellt (Code für die Wordclouds vgl. Duong Vu 2022). Hierbei mussten einige Stoppworte festgelegt werden, die in der Darstellung ausgeblendet werden. Das Vorgehen war dabei iterativ - geteilte Worte, die in den meisten Subgruppen häufig vorkamen und die Darstellung dominierten, wurden der Liste der Stopwords hinzugefügt.
# DF mit Abstracts einlesen
dfNodesAttributes = pd.read_csv(f'network_data/citation_network_NODELIST.csv', delimiter=',')
# Abstracts als Dict erstellen
abstract_dict = {}
for i, row in dfNodesAttributes.iterrows():
paper = dfNodesAttributes.id[i]
abstract_dict[paper] = str(dfNodesAttributes.abstract[i]).replace('.', '').replace(':', '').replace("'", "")
# Abstracts an DfNodes anfügen
def append_abstracts(df):
"""
Funktion erwartet ein DF mit einer Spalte label für die Paper IDs
"""
df['abstract']=df.label.map(abstract_dict)
df = df[df['abstract'].notna()]
return df
dfNodes = append_abstracts(dfNodes)
# Funktion zum Erstellen der Wordclouds
def generate_wordcloud(subgruppe, df):
"""
Funktion erwartet Nummer der Subgruppe und ein DF mit den Spalten modularity und abstract
"""
text = ''.join(df[df.modularity == subgruppe]['abstract'])
print ("There are {} words in subgroup: ".format(len(text)), subgruppe)
# Bestimmte, häufig vorkommende Wörter auslassen
stopwords = set(STOPWORDS)
stopwords.update(['one', 'two', 'based',
'use', 'using', 'used', 'user', 'users', 'proposed',
'paper', 'study', 'research', 'result', 'method', 'information', 'data',
'network', 'networks', 'social', 'analysis', 'model', 'models', 'structure', 'node', 'nodes'])
# Bild erzeugen
wordcloud = WordCloud(stopwords=stopwords, background_color="white").generate(text)
# Grafik anzeigen
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
Analyse: Die zentralsten Paper betrachten#
Mit dem untenstehenden Code können die Paper in den einzelnen Subgruppen (des Gesamtkorpus und der historischen Netzwerke) anhand ihrer Zentralitätsmaße sortiert und besonders wichtige Paper angezeigt werden. Wir nutzen diesen Code für die Interpretation der Subgruppen an späterer Stelle.
Sowohl die betrachtete Subgruppe (modularity), als auch nach frühestem Publikationsjahr (publication_year), sowie nach dem betrachteten Zentralitätsmaß (hinter sort_values) kann sortiert werden.
# Einzelne Gruppen nach zentralsten Papern durchsuchen
pd.set_option('display.max_colwidth', None)
# --> Gruppennr. (0-9) bei hinter 'modularity == ' eingeben
# --> Zentralitätsmaß, nach dem sortiert werden soll hinter 'sort_values()' eingeben
dfNodes[dfNodes.modularity == 7][['index', 'category', 'title', 'degree', 'in-degree', 'betweenness',
'modularity']].sort_values('in-degree', ascending=False).head(10)
| index | category | title | degree | in-degree | betweenness | modularity | |
|---|---|---|---|---|---|---|---|
| 765 | [anonymous] 2019 | Psychology Clinical; Public Environmental & Occupational Health; Social Sciences Interdisciplinary | operation of a network of sentinel centres that care for women in abortion situation. red clap musa component (ops symposium) | 223 | 223 | 0.000000 | 7 |
| 535 | mika p 2005 | Computer Science Artificial Intelligence; Computer Science Information Systems; Computer Science Software Engineering | flink: semantic web technology for the extraction and analysis of social networks | 63 | 59 | 0.000043 | 7 |
| 20 | xu jj 2005 | Computer Science Information Systems | crimenet explorer: a framework for criminal network knowledge discovery | 58 | 54 | 0.000003 | 7 |
| 503 | treur j 2016 | Behavioral Sciences; Computer Science Artificial Intelligence; Psychology Mathematical; Psychology Social | what is happening identifying and verifying emergent patterns | 38 | 30 | 0.000020 | 7 |
| 5017 | braha d 2004 | Computer Science Information Systems; Information Science & Library Science; Management | information flow structure in large-scale product development organizational networks | 32 | 28 | 0.000009 | 7 |
| 9092 | hargittai e 2010 | Communication; Sociology | predictors and consequences of differentiated practices on social network sites | 30 | 28 | 0.000011 | 7 |
| 307 | weng cy 2009 | Computer Science Information Systems; Computer Science Software Engineering; Telecommunications | rolenet: movie analysis from the perspective of social networks | 31 | 26 | 0.000011 | 7 |
| 4823 | memon n 2006 | Computer Science Information Systems; Computer Science Theory & Methods | practical approaches for analysis visualization and destabilizing terrorist networks | 33 | 26 | 0.000006 | 7 |
| 1653 | ereteo g 2009 | Computer Science Theory & Methods | analysis of a real online social network using semantic web frameworks | 30 | 25 | 0.000006 | 7 |
| 1806 | memon n 2008 | Computer Science Theory & Methods; Optics | a data mining approach to intelligence operations | 31 | 24 | 0.000021 | 7 |
# Einzelne Gruppen der historischen Netzwerke nach zentralsten Papern durchsuchen
pd.set_option('display.max_colwidth', None)
# --> Gruppennr. (0-9) bei hinter 'modularity == ' eingeben
# --> Zentralitätsmaß, nach dem sortiert werden soll hinter 'sort_values()' eingeben
dfNodes_2015[(dfNodes_2015.modularity == 3) & (dfNodes_2015.publication_year > 0)][['label', 'category', 'publication_year', 'title', 'in-degree', 'betweenness',
'modularity']].sort_values('in-degree', ascending=False).head(10)
| label | category | publication_year | title | in-degree | betweenness | modularity | |
|---|---|---|---|---|---|---|---|
| 90 | marsden pv 1987 | Anthropology; Sociology | 1987.0 | small networks and selectivity bias in the analysis of survey network data | 237 | 0.000033 | 3 |
| 311 | burt rs 1984 | Anthropology; Sociology | 1984.0 | network items and the general social survey | 146 | 0.000000 | 3 |
| 92 | mcpherson m 2006 | Sociology | 2006.0 | social isolation in america: changes in core discussion networks over two decades | 108 | 0.000356 | 3 |
| 26 | wellman b 1996 | Anthropology; Sociology | 1996.0 | are personal communities local? a dumptarian reconsideration | 89 | 0.000049 | 3 |
| 386 | wellman b 1997 | Anthropology; Sociology | 1997.0 | a decade of network change: turnover persistence and stability in personal communities | 76 | 0.000142 | 3 |
| 633 | bian yj 1997 | Sociology | 1997.0 | bringing strong ties back in: indirect ties network bridges and job searches in china | 73 | 0.000017 | 3 |
| 559 | berkman lf 2000 | Public Environmental & Occupational Health; Social Sciences Biomedical | 2000.0 | from social integration to health: durkheim in the new millennium | 65 | 0.000000 | 3 |
| 433 | heckathorn dd 1997 | Sociology | 1997.0 | respondent-driven sampling: a new approach to the study of hidden populations | 65 | 0.000037 | 3 |
| 149 | gould rv 1993 | Sociology | 1993.0 | collective action and network structure | 53 | 0.000003 | 3 |
| 1588 | campbell ke 1991 | Anthropology; Sociology | 1991.0 | name generators in surveys of personal networks | 51 | 0.000051 | 3 |
Analyse: Die Verteilung der WoS-Kategorien und die Wortverteilung betrachten#
Im Folgenden interpretieren wir nun die Ergebnisse unserer Datenanalyse sowohl für den Gesamtkorpus, als auch für die historischen Netzwerke zu unterschiedlichen Zeitpunkten. Wir gehen dabei chronologisch vor - hierfür sollen erneut die zentralen Entwicklungen in den verschiedenen Zeitabschnitten zur Orientierung dienen:
1995: Stand des Netzwerks kurz vor dem Eintritt der Physiker:innen
2005: Stand des Netzwerks kurz nach dem Eintritt der Physiker:innen und den ersten relevanten Veröffentlichungen
2015: Stand des Netzwerkes nachdem sich die ersten Wogen zwischen sozialen Netzwerk-Analyst:innen und Physiker:innen geglättet haben und sich das Forschungsfeld gewandelt hat
2022: Der aktuelle Stand des Forschungsfeldes
Funktionen definieren
def daten_vorbereiten_subgroups(dfNodes):
dfSubgroups = generate_modularity_df(dfNodes)
dfNodesExp = exp_df(dfSubgroups)
dfNodesPie = pie_df(dfNodesExp)
return dfNodesPie
def pie_clouds(anzahl, dfNodes, dfNodesPie):
for i in range(anzahl):
print('Subgruppe: ', i)
generate_piechart(i, dfNodesPie)
generate_wordcloud(i, dfNodes)
Ergebnisse für die historischen Netzwerke#
1995#
dfNodes_1995 = append_abstracts(dfNodes_1995)
dfNodesPie_1995 = daten_vorbereiten_subgroups(dfNodes_1995)
dfNodesPie_1995 = dfNodesPie_1995.iloc[: , 1:]
73 Subgruppen wurden ermittelt.
67 davon umfassen weniger als 20 Paper.
0 umfassen mindestens 150 Paper.
-----
Die größte Gruppe hat 84 Paper.
Die 10t-größte Gruppe hat 7 Paper.
-----
Das Zitationsnetzwerk hat 436 Knoten.
331 Knoten sind Teil einer Gruppe mit mindestens 7 Papern.
-----
Allen Papern in den 10 größten Gruppen sind zusammen insgesamt 577 Kategorien zugeordnet.
Das sind ca. 1.74 Kategorien pro Paper.
-----
Insgesamt 41 Kategorien sind in den 10 größten Subgruppen vertreten.
24 Kategorien, die in den jeweiligen Subgruppen weniger als 1.00 Mal vertreten waren, wurden gelöscht.
-----
1 Kategorien, die zu selten vertreten waren, wurden gelöscht.
Datengrundlage: Der Anteil an Papern, die bis 1995 erschienen sind, ist in unserem Korpus sehr klein. Von 436 Papern im Zitationsnetzwerk bleiben noch 331 in den 10 größten Subgruppen übrig. Die Größe der zehn Subgruppen reicht von 87 bis 7 Papern.
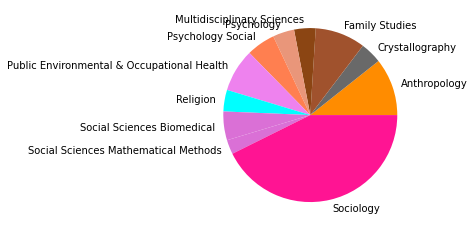
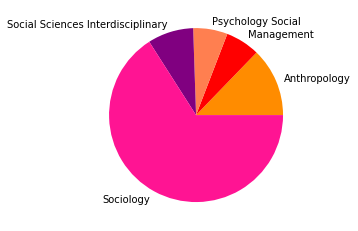
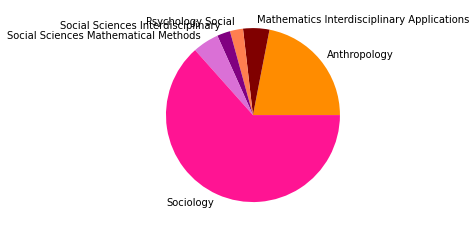
pie_clouds(10, dfNodes_1995, dfNodesPie_1995)
Subgruppe: 0
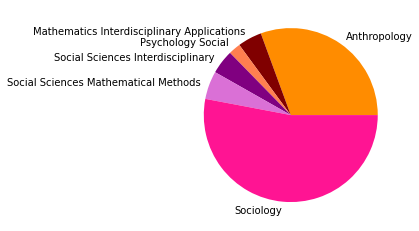
There are 21584 words in subgroup: 0
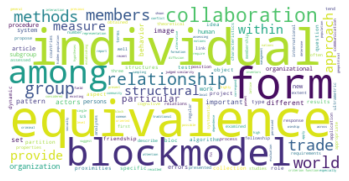
Subgruppe: 1
There are 36019 words in subgroup: 1

Subgruppe: 2
There are 9310 words in subgroup: 2

Subgruppe: 3
There are 20497 words in subgroup: 3

Subgruppe: 4
There are 21276 words in subgroup: 4
Subgruppe: 5
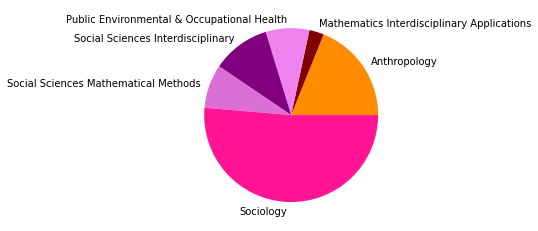
There are 15702 words in subgroup: 5
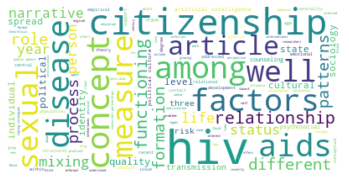
Subgruppe: 6
There are 5136 words in subgroup: 6
Subgruppe: 7
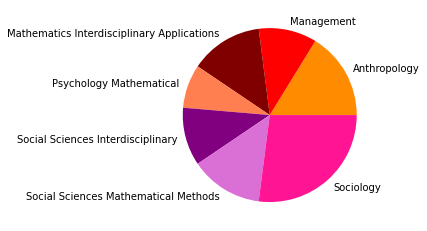
There are 7492 words in subgroup: 7

Subgruppe: 8
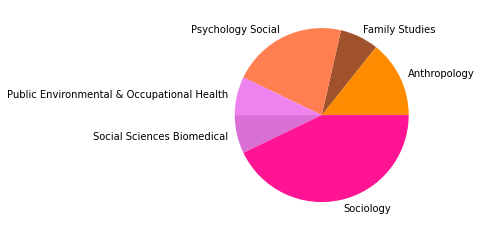
There are 2775 words in subgroup: 8
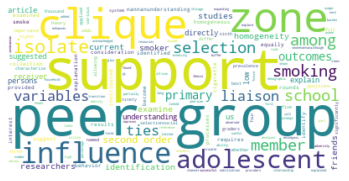
Subgruppe: 9
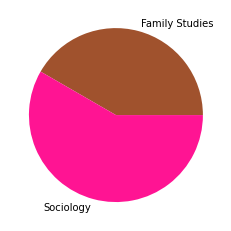
There are 3383 words in subgroup: 9
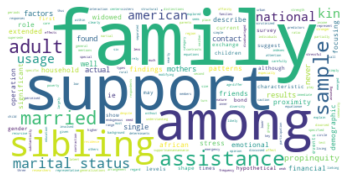
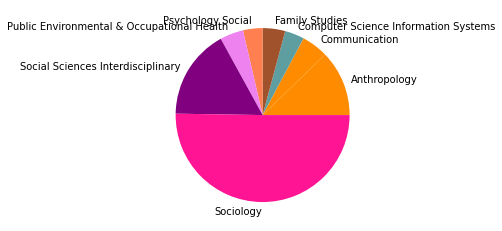
Wir haben den Zeitabschnitt bis 1995 als ersten Abschnitt gewählt, weil er das Feld der SNA zu der Zeit vor den populären Veröffentlichungen einiger Physiker:innen in den späten 1990er- und frühen 2000er-Jahren repräsentieren soll, in der das Feld hauptsächlich soziologisch besiedelt war. Dies spiegelt sich in den Kategorienzusammensetzungen der Subgruppen gut wieder, die alle größtenteils aus Soziologie und einem starken Anteil Anthropologie bestehen, und durch methodisch-sozialwissenschaftliche, psychologische, und vereinzelt in anderen Disziplinen angesiedelte Paper ergänzt werden.
Inhatlich scheint sich die größte Gruppe viel mit der auf Harrison White zurückgehenden Methode der Blockmodellanalyse zu beschäftigen, worauf die Begriffe “blockmodel” und “equivalence” (Subgruppe 0, Wordcloud) hindeuten. Dies spricht für eine in der soziologischen Tradition der Netzwerkanalyse verortete Methodendiskussion. In Hinblick auf die Wordclouds scheint die zweitgrößte Gruppe an Gruppenstrukturen und (Informations-)diffusion interessiert, die drittgrößte wiederum an Supportstrukturen in Netzwerken, und die viertgrößte an klassisch organisationssoziologischen Fragen nach Macht- und Einflussstrukturen in Organisationen. Die übrigen Gruppen weisen außerdem auf Themenschwerpunte der Gesundheits- und Familienforschung hin.
2005#
dfNodes_2005 = append_abstracts(dfNodes_2005)
dfNodesPie_2005 = daten_vorbereiten_subgroups(dfNodes_2005)
dfNodesPie_2005 = dfNodesPie_2005.iloc[: , 1:]
208 Subgruppen wurden ermittelt.
196 davon umfassen weniger als 20 Paper.
4 umfassen mindestens 150 Paper.
-----
Die größte Gruppe hat 369 Paper.
Die 10t-größte Gruppe hat 25 Paper.
-----
Das Zitationsnetzwerk hat 1775 Knoten.
1289 Knoten sind Teil einer Gruppe mit mindestens 25 Papern.
-----
Allen Papern in den 10 größten Gruppen sind zusammen insgesamt 2256 Kategorien zugeordnet.
Das sind ca. 1.75 Kategorien pro Paper.
-----
Insgesamt 115 Kategorien sind in den 10 größten Subgruppen vertreten.
41 Kategorien, die in den jeweiligen Subgruppen weniger als 1.67 Mal vertreten waren, wurden gelöscht.
-----
34 Kategorien, die zu selten vertreten waren, wurden gelöscht.
pie_clouds(10, dfNodes_2005, dfNodesPie_2005)
Subgruppe: 0
There are 308853 words in subgroup: 0
Subgruppe: 1
There are 218231 words in subgroup: 1

Subgruppe: 2
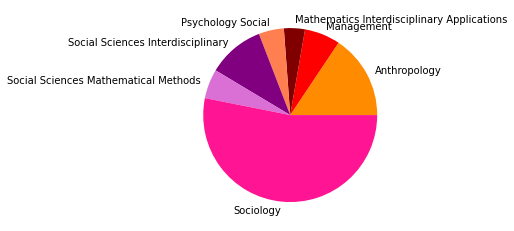
There are 165724 words in subgroup: 2

Subgruppe: 3
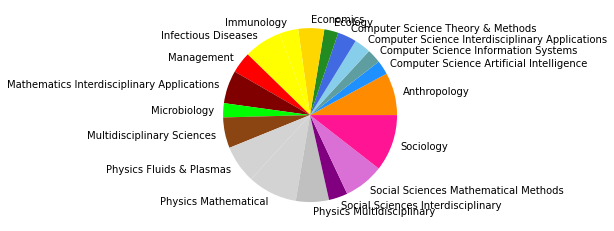
There are 145019 words in subgroup: 3
Subgruppe: 4
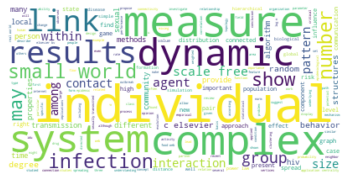
There are 64020 words in subgroup: 4

Subgruppe: 5
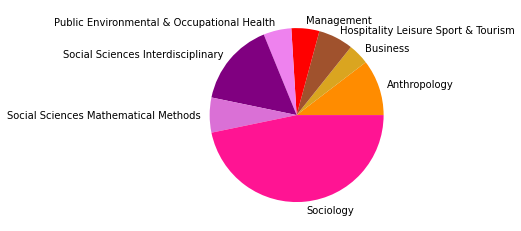
There are 32002 words in subgroup: 5

Subgruppe: 6
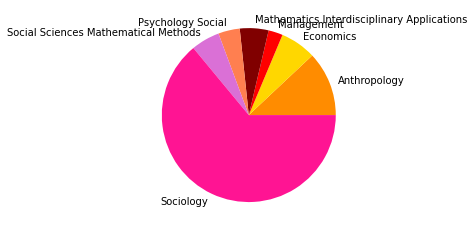
There are 46783 words in subgroup: 6

Subgruppe: 7
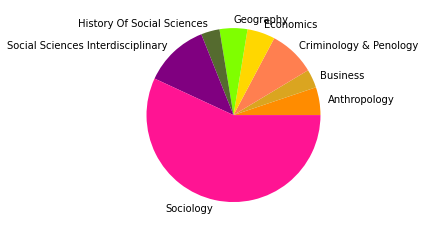
There are 40903 words in subgroup: 7
Subgruppe: 8
There are 24665 words in subgroup: 8
Subgruppe: 9
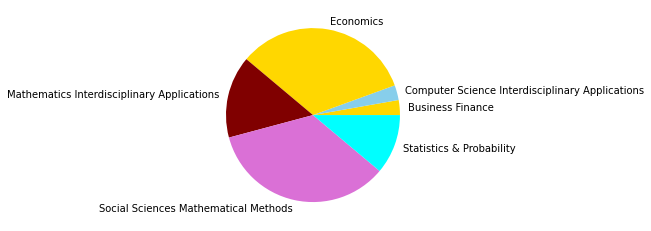
There are 18691 words in subgroup: 9

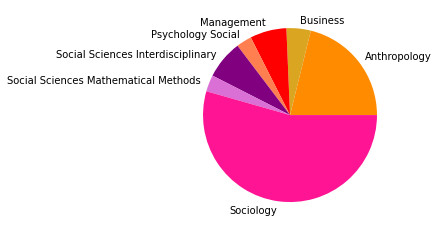
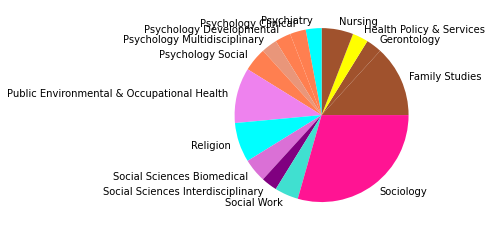
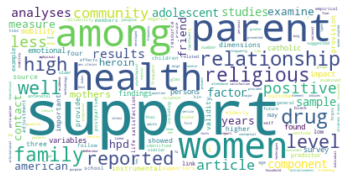
Der Zeitabschnitt bis 2005 erlaubt einen Einblick in Teile der Netzwerkliteratur (auch hier ist unser Korpus noch sehr klein) kurz nach dem Eintritt einiger bedeutender Physiker:innen ins Feld. Besonders in der Kategorienverteilung zeigt sich hier eine spannende Entwicklung: Während die klassische soziologisch-anthropologisch ausgerichtete Subgruppe (die den gesamten Korpus bis 1995 ausmachte) mit minimalen Ergänzungen aus anderen sozialwissenschaftlichen Disziplinen noch immer am häufigsten vertreten ist und die drei größten Gruppen ausmacht - thematisch bewegen sie sich abermals in den Bereichen Gruppenstrukturen, Support & soziales Kapital, sowie Organisationssoziologie -, taucht an vierter Stelle auf einmal eine Zitationsgemeinschaft in bunter Zusammensetzung ganz unterschiedlicher wissenschaftlicher Disziplinen auf.
Hier machen die Sozialwissenschaften nur noch etwa ein Viertel aller Kategorienzuordnungen aus, während Physik, Computer Science und Biologie/Immunologie zu ebenfalls fast gleichen Teilen vertreten sind. Spannend ist auch, dass inhaltlich Begriffe wie “complex” und “small world” zentral sind, worin sich die von den Physiker:innen besetzten Themengebiete, die schnell relevant für das gesamte Feld der Netzwerkanalyse wurden, deutlich zeigen. Diese viertgrößte Subgruppe kann als interdisziplinäres Cluster innerhalb der an sozialen Prozessen interessierten netzwerkanalytischen Literatur interpretiert werden, das den Eintritt der Physiker:innen ins Feld interessanterweise in den Kontext des etwa zeitgleichen Eintritts auch vielfältiger weiterer Disziplinen setzt.
Die am häufigsten zitierten Paper in dieser vierten, interdisziplinären Subgruppe kommen aus der Mathematik und der Physik und beschäftigen sich mit komplexen Netzwerken (Newman 2003, Albert 2000, Pastor-Satorras 2001). Einen hohen In-Degree haben in dieser Gruppe außerdem soziologisch-anthropologische Paper aus den 1990er-Jahren zu Zentralitätsmaßen (so etwa Freeman 1991, Rothenberg 1995). Neben den klassisch-soziologischen und dem neuen interdisziplinären Cluster zeigt sich auch eine Weiterentwicklung einer hauptsächlich gesundheitswissenschaftlich ausgerichteten Gruppe in Subgruppe 8.
2015#
dfNodes_2015 = append_abstracts(dfNodes_2015)
dfNodesPie_2015 = daten_vorbereiten_subgroups(dfNodes_2015)
dfNodesPie_2015 = dfNodesPie_2015.iloc[: , 1:]
700 Subgruppen wurden ermittelt.
680 davon umfassen weniger als 20 Paper.
8 umfassen mindestens 150 Paper.
-----
Die größte Gruppe hat 3135 Paper.
Die 10t-größte Gruppe hat 100 Paper.
-----
Das Zitationsnetzwerk hat 12523 Knoten.
10697 Knoten sind Teil einer Gruppe mit mindestens 100 Papern.
-----
Allen Papern in den 10 größten Gruppen sind zusammen insgesamt 20829 Kategorien zugeordnet.
Das sind ca. 1.95 Kategorien pro Paper.
-----
Insgesamt 204 Kategorien sind in den 10 größten Subgruppen vertreten.
88 Kategorien, die in den jeweiligen Subgruppen weniger als 6.67 Mal vertreten waren, wurden gelöscht.
-----
71 Kategorien, die zu selten vertreten waren, wurden gelöscht.
pie_clouds(10, dfNodes_2015, dfNodesPie_2015)
Subgruppe: 0
There are 3381500 words in subgroup: 0

Subgruppe: 1
There are 2694981 words in subgroup: 1

Subgruppe: 2
There are 1697402 words in subgroup: 2

Subgruppe: 3
There are 1225735 words in subgroup: 3
Subgruppe: 4
There are 707307 words in subgroup: 4

Subgruppe: 5
There are 735465 words in subgroup: 5

Subgruppe: 6
There are 535099 words in subgroup: 6
Subgruppe: 7
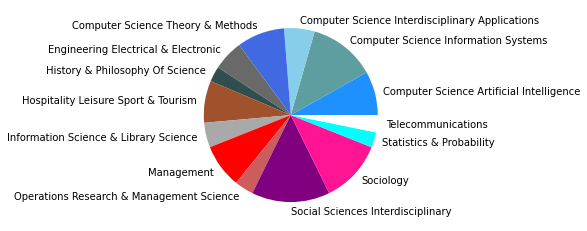
There are 209199 words in subgroup: 7

Subgruppe: 8
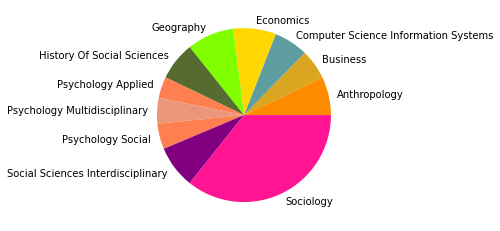
There are 108451 words in subgroup: 8

Subgruppe: 9
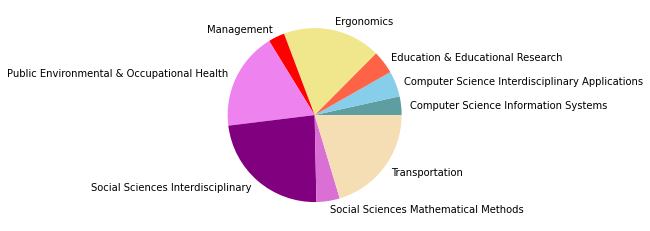
There are 135505 words in subgroup: 9
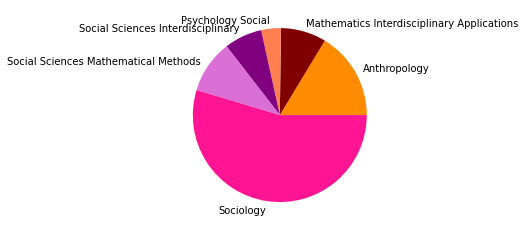
In der einschlägigen wissenschaftsgeschichtlichen Literatur zum Thema soziale Netzwerkanalyse wird ein großer Umbruch mit der Veröffentlichung prominenter Paper aus der Physik in den frühen bis mittleren 2000er-Jahren verortet. Der Einzug der Disziplinen Physik und Computer Science um diese Zeit konnte im vorherigen Zeitabschnitt bis 2005 tatsächlich nachgewiesen werden, weil ein großes, interdisziplinäres Cluster auftaucht, in dem die Soziologie bzw. Sozialwissenschaften nur eine untergeordnete Rolle spielen. Die Ergebnisse des Zeitabschnitts bis 2015 legen nun allerdings nahe, dass Entwicklungen und Verschiebungen im Feld der SNA nach diesen Ereignissen keineswegs aufhörten - vielmehr zeigt sich nun 10 Jahre später noch einmal ein sehr verändertes Bild.
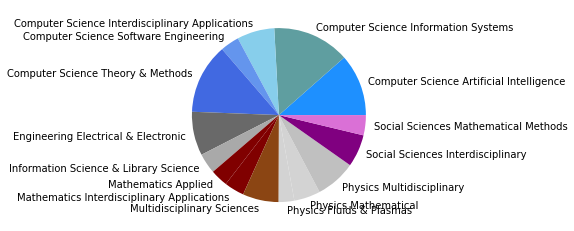
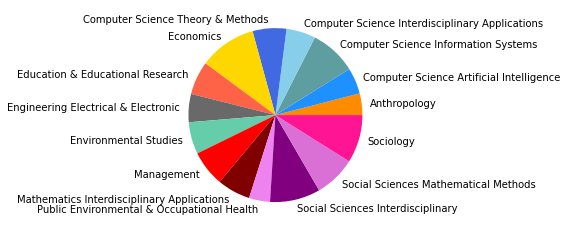
Eine der wichtigsten Veränderungen, die sich unter Hinzunahme der nächsten 10 Jahre in unserem Corpus zeigt, ist sicherlich darin zu erkennen, dass die recht homogen in Soziologie & Anthropologie angesiedelte Zitationsgruppe auf Platz zwei der größten Zitationscluster verdrängt worden ist. An ihrer Stelle steht nun eine computerwissenschaftlich dominierte Gruppe (0), die sich zusätzlich aus Informations- und Bibliothekswissenschaften, Physik, Mathematik und interdisziplinären Sozialwissenschaften zusammensetzt - den Wordclouds nach zu urteilen mit einem Interesse für komplexe, dynamische Systeme. Die (an den Zentralitätsmaßen gemessen) wichtigsten Paper dieser Gruppe, die außerdem nach 2005 erschienen sind, beschäftigen sich den Titeln nach zu urteilen vor allem mit Fragen nach sozialen Dynamiken (Castellano 2009, Szell 2010), Dynamiken komplexer Netzwerke (Boccaletti 2006), Gruppenentwicklung (Palla 2007) und Möglichkeiten von community detection (Fortunato 2007, Lancichinetti 2009). In den zehn wichtigsten Papern ab 2010 werden außerdem auch Multilayer bzw. -level-Netzwerke behandelt (Boccaletti 2014, Barnett 2014).
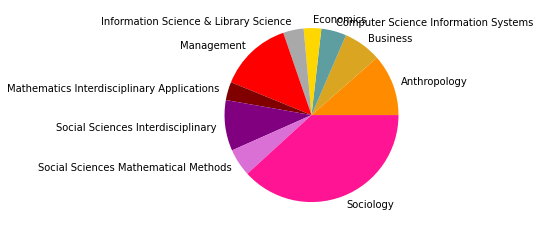
Schaut man sich die Wordcloud der zweitgrößten, klassisch soziologisch/anthropologischen Zitationsgruppe (1) an, so scheint diese organisationssoziologisch geprägt zu sein und sich außerdem mit individuellen Positionen und Gruppen zu beschäftigen. Die meistzitierten, ab 2005 erschienen Paper in dieser Gruppe beschäftigen sich allerdings hauptsächlich mit methodischen Themen wie fehlenden Daten (Kossinets 2006) und random graph models (Robins 2007, Snijders 210, Snijders 2006), was für eine lebendige Methodendiskussion auch im soziologischen Kontext spricht, die eventuell durch die Entwicklungen in den 2000ern befeuert wurde. Anhand der drittgrößten Gruppe (2) zeigt sich außerdem abermals die zunehmende Interdisziplinarität unseres Corpus, die schon im Netzwerk bis 2005 erstmals erfasst wurde: Diese Zitationsgruppe setzt sich aus Sozialwissenschaften, Computer Science, vielfältigen sozial-, verhaltens- und gesundheitswissenschaftlichen Disziplinen, sowie Umweltwissenschaften und Mathematik zusammen.
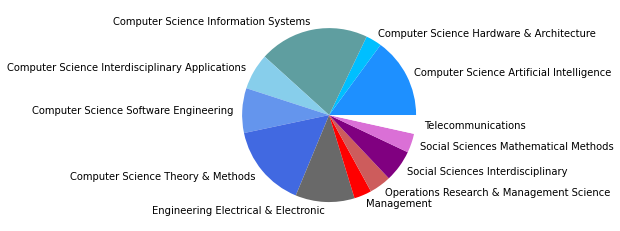
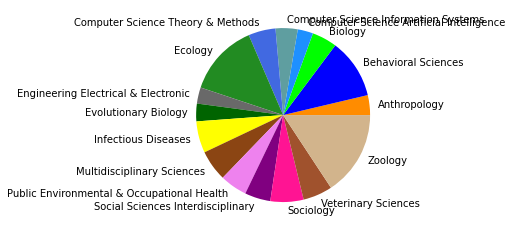
Neben diesen drei größten Zitationsgruppen, die abermals auf disziplinäre Verschiebungen im Feld der SNA hindeuten, zeigt sich auch in den übrigen Gruppen eine Diversifizierung: So taucht nur noch eine einheitlich soziologisch-anthropolgische Subgruppe auf (3), dafür aber eine starke computerwissenschaftliche Gruppe (4), sowie zwei Gruppen, in denen sich diese beiden Felder überschneiden (6, 7). Außerdem zeigt sich ein Cluster mit Bezug zu Ökologie/Zoologie (5), und zwei weitere interdisziplinäre sozialwissenschaftliche Cluster (8, 9).
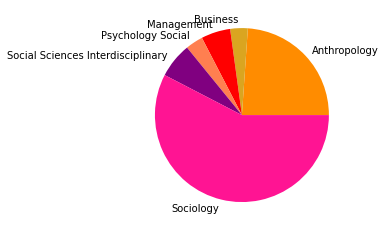
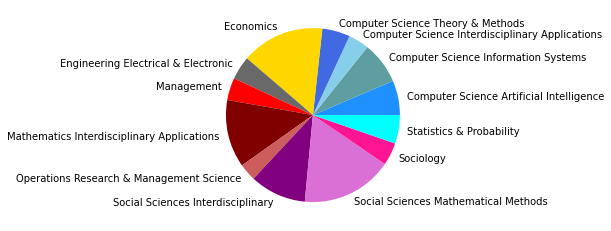
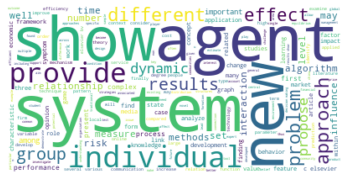
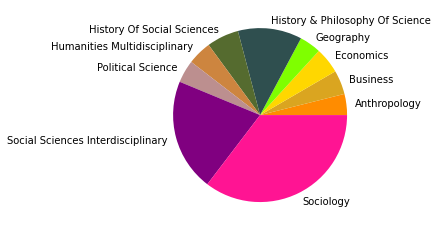
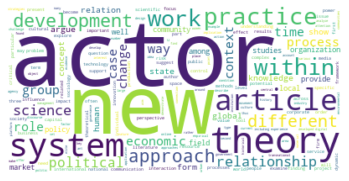
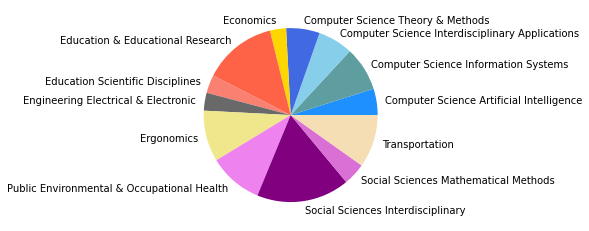
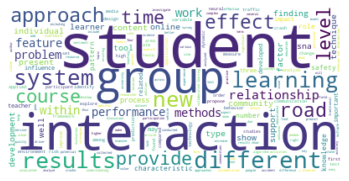
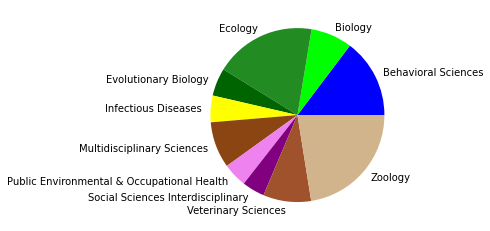
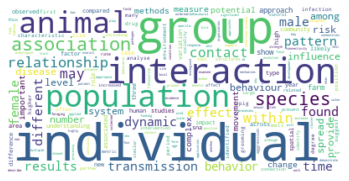
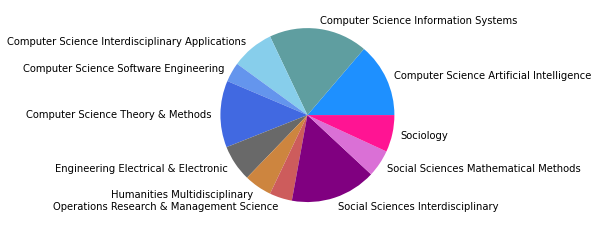
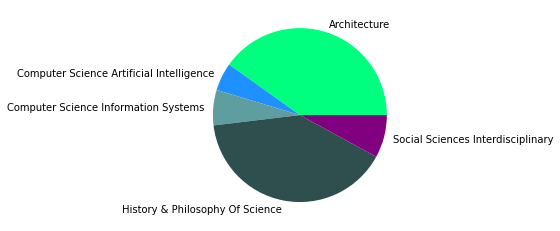
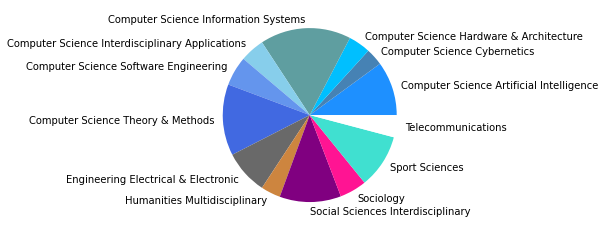
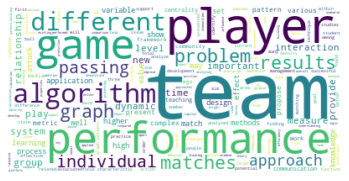
Gesamtkorpus bis 2022#
pie_clouds(10, dfNodes, dfNodesPie)
Subgruppe: 0
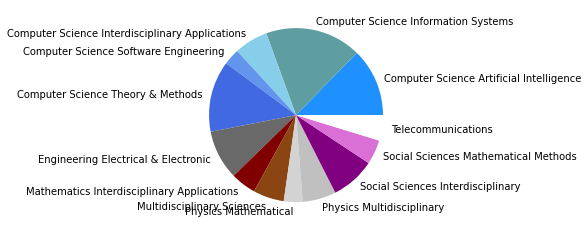
There are 9648298 words in subgroup: 0

Subgruppe: 1
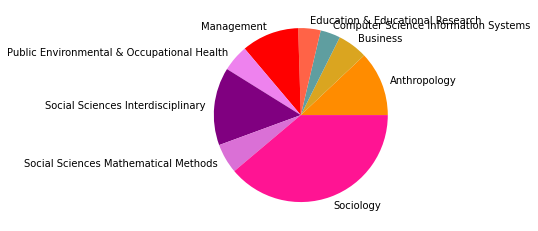
There are 7705897 words in subgroup: 1
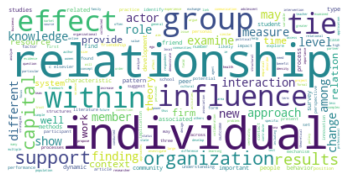
Subgruppe: 2
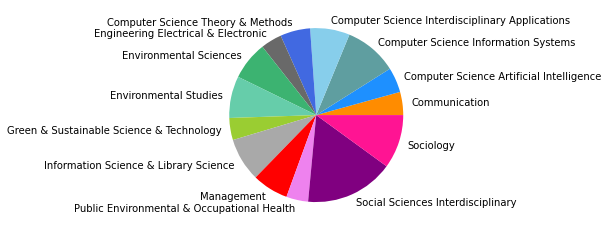
There are 8051984 words in subgroup: 2

Subgruppe: 3
There are 2302916 words in subgroup: 3
Subgruppe: 4
There are 1840539 words in subgroup: 4
Subgruppe: 5
There are 1656194 words in subgroup: 5
Subgruppe: 6
There are 1657736 words in subgroup: 6
Subgruppe: 7
There are 950373 words in subgroup: 7

Subgruppe: 8
There are 194234 words in subgroup: 8

Subgruppe: 9
There are 204168 words in subgroup: 9
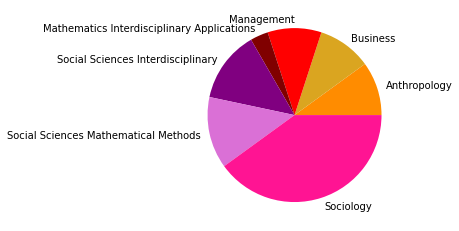
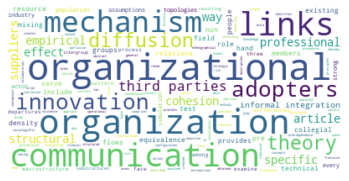
Vergleicht man zuletzt das Zitationsnetzwerk bis 2015 mit unserem Gesamtkorpus, dessen Veröffentlichungen bis 2022 reichen, so fallen in den kleineren Gruppen abermals einige Änderungen auf, während die drei größten Zitationsgruppen beider Netzwerke sich bis auf minimale Verschiebungen (so zum Beispiel der Zuwachs an Umweltwissenschaften in Subgruppe 2) in den Kategorienverteilungen gleichen.
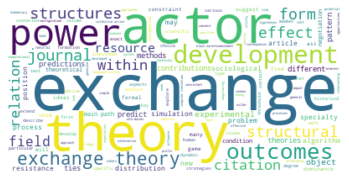
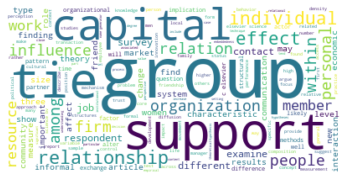
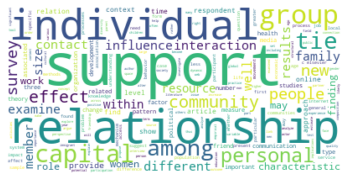
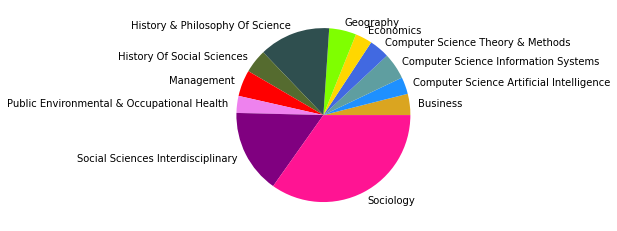
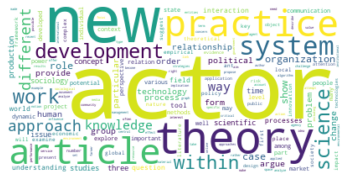
Der erste große Unterschied wird in der viertgrößten Zitationsgruppe deutlich, die 2015 aus hauptsächlich soziologisch-anthropologischen Papern gebildet wurde, und 2022 eine interdisziplinäre Zusammensetzung aus Sozialwissenschaften, Computer Science, Mathematik und Management/Wirtschaft bildet. Erstere Gruppe scheint im Gesamtkorpus auf Rang 5 gerückt zu sein. Ein näherer Vergleich dieser beiden soziologisch dominierten Gruppen mit Einbezug der Wordclouds legt dabei eine eventuelle thematische Verschiebung nahe: Während bis 2015 “support” und “capital” wichtige Worte sind, sind bis 2022 u.a. “actor”, “new”, “theory” und “system” von Bedeutung. Ein Blick in die Paper mit den höchsten Zentralitätsmaßen zeigt allerdings, dass es sich wahrscheinlicher um zwei verschiedene soziologische Cluster handelt, ersteres in der SNA verortet, und letzteres in der Akteur-Netzwerk-Theorie (hier sind Latour, Callon und Knorr-Cetina prominent). Dieses Ergebnis zeigt, dass in unserem Korpus auch viel ANT-Literatur repräsentiert ist. Da diese bisher nur wenig Berührungspunkte mit interdisziplinärer SNA-Forschung hat, ergibt es Sinn, dass diese Literatur scheinbar im einzigen recht homogen-sozialwissenschaftlichen Zitationscluster angesiedelt ist - umgekehrt deutet das aber auch darauf hin, dass SNA-Literatur im Netzwerk bis 2022 nur noch in interdisziplinären Clustern vorkommt, was unsere These der zunehmenden Interdisziplinarität des Feldes stärkt.
In den übrigen fünf Zitationsgruppen findet sich genau so ein interdisziplinäres Cluster aus Soziologie und Computerscience, einmal mit einem großen Anteil an Bildungswissenschaften (5), und einmal mit Anteilen aus dem Bereich Engineering (7). Spannend ist außerdem ein recht eindeutig aus den Feldern Biologie, Ökologie, Verhaltenswissenschaften und Infektionskrankheiten zusammengesetztes Cluster (6), das sich auch im Korpus bis 2015 schon zeigte (5) und sich nun verfestigt zu haben scheint. Zusätzlich zeigt sich noch ein Wissenschaftsgeschicte/Architekturcluster (8), das vermutlich durch unseren spezifischen Search-String zu erklären ist, und ein weiters fast ausschließlich computerwissenschaftliches Cluster (9).
Zusammenfassung#
In unserer deskriptiven Analyse der Paper in den zehn größten Zitationsgruppen der Netzwerke jedes Zeitabschnitts (bis 1995, 2005, 2015 und 2022) anhand von Kategorienverteilungen und wichtigen Worten in den Abstracts, konnten wir vor allem eine wachsende Interdisziplinarität des Korpus feststellen. Besonders die Verteilungen der zugeordneten Kategorien haben sich über die Zeitabschnitte hinweg stark verändert. Hierbei tauchten gewisse Typen an Zitationsgruppen häufiger auf: Im Netzwerk bis 1995 konnten fast alle Subgruppen als relativ homogene soziologisch-anthropologische Gruppen beschrieben werden, die nur hin und wieder durch Psychologie, Familienwissenschaften und andere sozial- und verhaltenswissenschaftliche Disziplinen ergänzt wurden. Dieser Typus macht auch 2005 noch die Hälfte aller Subgruppen aus und verliert sich dann nach und nach - 2015 scheint er nur noch für das eigentlich nicht der SNA zugeordnete Thema der Akteur-Netzwerk-Theorie gültig zu sein, während nun häufiger interdisziplinäre Cluster mit Schwerpunkt auf Sozialwissenschaften und Computerscience auftauchen. Dies spricht dafür, dass das Feld sozialer Netzwerkanalyse im Laufe der Zeit von immer mehr Disziplinen bespielt wird und sich aus der eindeutigen Zuordnung zur Soziologie und Anthropologie herausgelöst hat. Eine weitere wichtige Erkenntnis ist außerdem die Wichtigkeit der Computer Science, die immer stärker zu werden scheint. Unklar ist an dieser Stelle allerdings, ob es sich um rein computerwissenschaftliche Paper handelt, oder um solche, die diese Kategorienzuordnung noch mit weiteren etwa aus den Sozialwissenschaften teilen. Trotzdem kann festgehalten werden, dass sie in unserem Korpus bis 2022 die größte Zitationsgemeinschaft dominiert und sonst in fast allen weitern Subgruppen mit meist gewichtigen Anteilen vorkommt.